Nota: si ya tuviste ramos de SQL o similares, puedes omitir esto, a menos que quieras sacar ejemplos o estés aburrido, o qué se yo. No me voy a enojar :)
Y claramente espero que sepas algo de R

Si cuando piensas en "bases de datos", lo primero que se te viene a la mente, es una planilla tipo Excel, ¡esta nota es para ti!
Excel es una herramienta útil, si, que la usarás toda tu vida, probablemente también, pero que es la forma de hacer bases de datos, mmm, no mucho, o muchas veces es más una consecuencia de tener una base de datos, siendo específicos, el Excel es así como una "tabla desnormalizada".
¿Eso implica la existencia de una versión "normalizada"? Así es, en realidad implica 3 formas de "normalización", las llamadas primera, segunda y tercera forma normal.
No necesitan saber en detalle esto, a menos que se quieran dedicar al área de Desarrollo de Bases de Datos, aunque no es mala idea manejar y explorar esos conceptos, y hay muy buenos videos en Yutu sobre el tema, como para detenernos en eso aquí.
Quiero ir al punto de que una consecuencia directa de esta lógica de normalización, es que en la realidad no trabajas con una planilla "todo en uno", tipo esto.

Para que se entienda, digamos que tenemos 5 personas, donde a cada una le medimos una variable X cualquiera (eg. edad, coeficiente intelectual, estatura, etc), y de cada persona registramos el lugar de donde proviene y que rankeen 3 tipos de preferencias de mayor a menor preferencia: 1) abc, 2) cdf, 3) hij. Estas preferencias podrían ser cualquier cosa, 3 marcas de zapatos, 3 candidatos o partidos políticos, 3 colores, etc.
Esta es una tabla común que se puede recuperar por ejemplo de un Google Form, y que muchos han visto, pero ¿Qué pasaría si les dijera que esta tabla podría verse así?

Esto es lo que se conoce como un modelo Entidad-Relación, y es una versión mega resumida de como se ve una base de datos de verdad. Es a partir de este modelo que puedes recuperar una vista que contenga todas las tablas, o más bien, sus columnas, en una sola planilla para procesarla, y para ello uno usa consultas o "Querys", a través de un lenguaje institucionalizado que tal vez hayan escuchado: SQL (tiene algunas variaciones como plSQL o MySQL, pero las diferencias no son muchas, también existe lenguajes noSQL para datos no estructurados, aunque una discusión respecto a sus ventajas y si realmente superan a SQL).
Un ejemplo de SQL es esta breve sentencia.
SELECT * FROM personas
Al ejecutarla, les saldrá una tabla como esta

SELECT p.nombre as nombre, pr.abc as abc, pr.hij as hij, pr.cdf as cdf FROM personas p JOIN preferencias pr ON p.id_preferencias = pr.id
Y produce el siguiente resultado

Miren el código y el resultado, y traten de hacer la correlación. Noten que a la tabla "personas", le puse un alias "p", mientras que a "preferencias" un alias "pr", esto hace más fácil llamar cada elemento de su respectiva tabla, y es especialmente útil cuando las tablas tienen columnas con un mismo nombre.
Así también fíjense que desde la tabla personas usé la respectiva llave foránea indicando en qué (ON) debía coincidir con las tablas a unir, en este caso la llave foránea id_preferencias de la tabla personas, con la respectiva llave primaria a la que apunta, la id de la tabla preferencias.
E igual que la Query anterior, toda esta sentencia es traducible al castellano. En SQL básicamente estamos diciendo: "Tráeme esta variable de esta tabla y ponle este alias (ej. a p.nombre solo "nombre"), desde la tabla a la que llamamos de esta manera (ej. tabla personas como "p"), y esa tabla anterior me la juntas (JOIN) con la otra tabla que llamaremos de esta manera (ej. preferencias como "pr"), donde su punto de coincidencia es la llave foránea de mi primera tabla con la llave primaria de la otra tabla".
Con esto espero haberte motivado a aprender algo de SQL, que no es malo, pero si eres porfiado, te voy a mostrar como esta lógica es terrible útil entenderla cuando estas armonizando o haciendo un empalme de múltiples datasets, esta parte es entrete si te gusta la política comparada.
Digamos que quieres encontrar alguna relación entre democracia, desarrollo o desigualdad. Eso involucra armonizar a lo menos 2 datasets distintos, uno de democracia y otro con estadísticas de desarrollo. Para este ejemplo usaremos la del V-Dem y las del Banco Mundial (BM).
Por suerte para nosotros los países también tienen una "llave primaria", de las que las 2 más famosas y usadas, sobre todo en ciencias políticas, es la de Correlates of War (COW) y las ISO. Cada una tiene una versión numérica y otra en letras, si tu dataset es demasiado gigante, prefieran la versión numérica, ya que son más eficientes para las Querys. Respecto a las versiones con letras, en el caso de la ISO, tiene 2 versiones (ni puta idea porque), una de 2 letras y una de 3 letras, generalmente denotados por "iso2c" o "iso3c" respectivamente.
Pero partamos por lo básico, llamemos a nuestros datasets. Para eso usaremos las librerías del V-Dem (que pueden encontrar acá) y la del Banco Mundial (disponible acá). Junto con estas usaremos la librería contrycode, que nos permite armonizar distintos códigos regionales e incluso unidades agregadas, como continentes o regiones (eg. América del sur, centro y norte, etc).
De la librería vdem, traeremos el índice de democracia electoral, codificado como "v2x_poliarchy".
library(tidyverse) library(countrycode) library(vdem) library(WDI) democracia <- extract_vdem(name_pattern = "v2x_polyarchy", include_external = F)
El parámetro "include_external" es para traer solo los datos que vamos a usar, y no dependencias externas asociadas a la construcción del índice, más detalles en la documentación de la librería.
El data set importado se ve así:

Aunque no se señala explícitamente en la variable subrayada, esta está en formato iso3c, y es la variable que usaremos como llave primaria, aunque es necesaria cierta modificación previa.
Por otro lado para temas de desarrollo, veremos el índice de pobreza US$5.50, esto es, el porcentaje de personas que vive con esa cantidad de dinero al día, la cual marca una línea de la pobreza comparable a nivel internacional (ojo no es una comparación perfecta, ninguna lo es, pero si da una idea sobre todo en países relativamente homogéneos).
Para eso le indicamos el código de la variable (ver el link anterior sobre la librería), y el intervalo de años entre los que se quieren los datos.
pov550usd <- WDI(indicator = "SI.POV.UMIC", start = 1980, end = 2020)
El dataframe que esto nos devuelve se ve así:

pov550usd$iso3c <- countrycode(pov550usd$iso2c, origin = "iso2c", destination = "iso3c")
Al ejecutar les dirá que ciertos códigos no los reconoce. Estos corresponden a divisiones regionales propias del Banco Mundial tales como la OCDE, la eurozona, países árabes, etc. Podemos ignorarlo ya que nos centraremos solo en los países.
Ahora viene el razonamiento anterior sobre llaves foráneas y primarias. Recordemos que el concepto de llave primaria es la que identifica plenamente al caso, que para nosotros es la fila o "tupla" con datos. Pero si observan los datasets arriba, el código de cada país está repetido dado que es el mismo país en distintos años, por lo que si quisiéramos fusionar ambas tablas usando la columna iso3c, nos daría error.
Para evitar ello, podemos construir una llave primaria en ambas tablas concatenando la iso3c y el año, lo que se conoce como una llave compuesta, para nosotros se vería así:
democracia$pk <- paste0(democracia$vdem_country_text_id, democracia$year) pov550usd$fk <- paste0(pov550usd$iso3c, pov550usd$year)
Les puse pk (primary key) y fk (foreign key) solo como analogías, para que se entienda, pueden ponerle el nombre que ustedes gusten.
Con esto estamos listos para juntar ambas series, pero falta un detalle. Si observan el código de SQL, tenemos por así decirlo, una tabla que recibe los datos de otra. Aquí hay varias formas en que una tabla puede recibir datos, por ejemplo manteniendo todos los de la tabla original, y trayendo solo los coincidentes de la tabla externa, dejando los no coincidentes como valores nulos, lo que se conoce como "LEFT JOIN" o unir solo los elementos coincidentes de ambas tablas e ignorar los no coincidentes, llamado "INNER JOIN". Esto es muy en la lógica de conjuntos, que de hecho es la teoría detrás de estas cosas, ver la siguiente imagen sobre los distintos tipos de JOIN.

Si nuestros datos estuvieran en un servidor de SQL, y quisiéramos una consulta que trajera el año y las variables de interés, se vería así:
SELECT d.year as year,
p.iso3c as country,
d.v2x_polyarchy as democracy, p.SI.POV.UMIC as poverty550 FROM democracia d INNER JOIN pov550usd p ON d.pk = p.fk
En este caso usamos un INNER JOIN, para traer un dataset con casos coincidentes, esto es, tomando solo las llaves comunes a ambas tablas, excluyendo aquellas que no siguiendo la lógica mencionada.
Esto es traducible a R por medio de comandos dplyr incluidos en la librería tidyverse, lo que se vería así:
join <- democracia %>% inner_join(pov550usd, by= c("pk"="fk")) %>% select(year.x, vdem_country_text_id, v2x_polyarchy, SI.POV.UMIC)
Comparen ambos códigos, y notaran que en el código de R están los mismos elementos de la Query de SQL, solo que en un orden distinto, por ejemplo la sentencia SELECT está al final, y no entremedio del JOIN (ojo, el select() de hecho es opcional, solo que sin este te traería columnas que puedes no necesitar). Si bien se puede poner entre medio, no se ve muy bien. Notar también que como "year" tiene el mismo nombre en ambas tablas, se le concatena un ".x" o un ".y" (no mostrado) para identificar al año de qué tabla nos referimos, similar a cuando usábamos un alias en el JOIN de SQL.
El resultado de esta Query nos da la siguiente tabla:
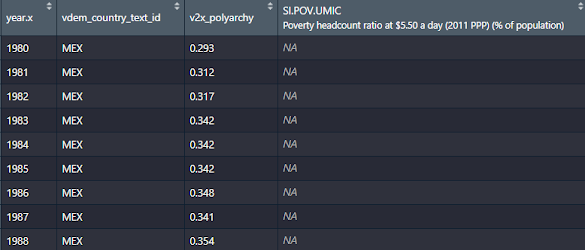
¿En qué se traduce el INNER JOIN? Bueno el dataset de democracia extiende su serie desde 1789 hasta el 2019, mientras que la del Banco Mundial parte desde 1980 al 2020, así que como la llave primaria está compuesta por el año, los valores coincidentes entre ambas tablas corresponden a los del año 1980 al 2019.
¿Y si quisiera sumar una tercera tabla? Pues sigue la misma lógica, te dejo un código de como debiera verse con 3 tablas ficticias, donde la tabla 1 tiene una pk, y las otras dos tablas tienen una fk1 y fk2 respectivamente. Esto se ve así:
tabla1 %>% left_join(tabla2, c("pk"="fk1")) %>% left_join(tabla3, c("pk" = "fk2"))
Ojo, estamos asumiendo que la tabla 1 guarda una relación con la 3, ello puede no ser así, por ejemplo pudiera existir una relación solo entre la tabla 2 y 3, en cuyo caso habría que cambiar el c("pk"="fk2") por c("fk1"="fk2").
¿Te cambia esto la idea que tenías de bases de datos? ¿Aun te atreverías a llamar "base de datos" a tu éxcel?
Excelente post. Desde la humilde trinchera del spss uno se da cuenta de que ese programa no hace ninguna wea xD y es necesario mudarse al Rstudio.
ReplyDeleteBajo tu juicio, ¿es difícil dicha migración?
Saludos.
Para nada!!
DeleteDe hecho yo partí usando SPSS mis primeros años de trabajo, como todos creo, es el software que nos enseñan.
En internet hay demasiados recursos para aprender, es solo cosa de ponerle empeño :)
Genial. Buscaré de donde partir, ya que he visto algunos recursos que sobrepasan mi conocimiento.
DeleteMuchas gracias por responder. Seguiré atento al blog para seguir aprendiendo.
Saludos.